6 algorytmów sztucznej inteligencji dostało po 10 000 dolarów, identyczne dane i wytyczne, by handlować na prawdziwych giełdach kryptowalut bez udziału człowieka. Jaki rezultat? Po 17 dniach 4 z nich ukończyły pierwszy etap badania z deficytami dochodzącymi do 62%. Zwycięzca wypracował 22% zysku.

3 listopada zakończyła się inauguracyjna edycja turnieju Alpha Arena, którego zamiarem było zweryfikowanie możliwości dużych modeli językowych w obszarze handlu kwantytatywnego na rynku kryptowalut. Organizatorem było Nof1 – określające się mianem pierwszego laboratorium naukowo-badawczego koncentrującego się na sztucznej inteligencji w powiązaniu z rynkami finansowymi.
W Alpha Arena wzięło udział 6 dużych modeli językowych (LLM):
- GPT-5 od OpenAi,
- Gemini 2.5 Pro od Google,
- Claude Sonnet 4.5 od Anthropic,
- Grok 4 od xAI Elona Muska,
- chiński DeepSeek v3.1,
- Qwen3-Max od Alibaba."
Sztuczna inteligencja prowadzi transakcje kryptowalutami
Rywalizacja zaczęła się 18 października. Każdy model otrzymał analogiczne wskazówki i dane wejściowe, 10 000 dolarów kapitału początkowego i dostęp do zdecentralizowanej giełdy Hyperliquid.
W celu uproszczenia zadania, Nof1 ograniczył możliwe akcje dla modeli do otwierania pozycji długich i krótkich oraz ich zachowywania bądź likwidowania. Wybór aktywów zredukowano do sześciu popularnych kryptowalut na Hyperliquid: BTC, ETH, SOL, BNB, DOGE i XRP.
Twórcy badania zaznaczali, że wybrali rynek kryptowalut i Hyperliquid z trzech konkretnych powodów:
- dostępności przez całą dobę, przez 7 dni w tygodniu, co umożliwiało nieustanne śledzenie zachowania modeli,
- obfitości i łatwej dostępności danych, wspierające analizę i transparentny audyt
- szybkości i solidności Hyperliquid oraz prostej integracji platformy z modelami LLM.
Kryptowalutowa klęska Chatu GPT
Chat GPT-5 i Gemini rozpoczęły turniej oscylując wokół punktu wyjścia, lecz już po kilku dniach zaczęły notować znaczne straty i nie odrobiły ich aż do zakończenia konkursu. Ich finalny rezultat nie odbiegał znacząco od liczb, które dało się zaobserwować piątego dnia konfrontacji.
GPT-5 od OpenAi okazał się najmniej skutecznym modelem językowym w teście Alpha Arena. Z początkowych 10 000 dolarów na 3 listopada pozostało mu 3733 dolary, co implikowało stratę na poziomie 62,7%.
Model Google Gemini zajął przedostatnie miejsce z uszczupleniem kapitału o 56,7% do 4329 dolarów. Grok z laboratorium xAI stracił do 3 listopada 45,3% kończąc pierwszy etap z depozytem w wysokości 5469 dolarów.
Ponad 100% profitu DeepSeek. Do pewnego momentu
Claude Sonnet wypadł najlepiej spośród "zachodnich" modeli LLM, tracąc 30,8% i kończąc turniej z wynikiem 6918 dolarów. Dwa czołowe miejsca przypadły chińskim modelom DeepSeek i Qwen3-Max, które również dominowały przez cały czas trwania testu.
Po 10 dniach rywalizacji, 27 października, DeepSeek górował nad resztą konkurencji zarabiając na czysto ponad 13 000 dolarów. Qwen3-Max dotrzymywał mu kroku podwajając początkowy kapitał. Późniejsze spadki na rynku kryptowalut wpłynęły jednak negatywnie na końcowe rezultaty.
Ostatecznie pierwszą edycję Alpha Areny wygrał Qwen3-Max od chińskiego giganta Alibaba, kończąc zmagania z wynikiem 12 231 dolarów, co stanowi 22,3% zysku. DeepSeek zarobił 10 489 dolarów czyli 4,9%.
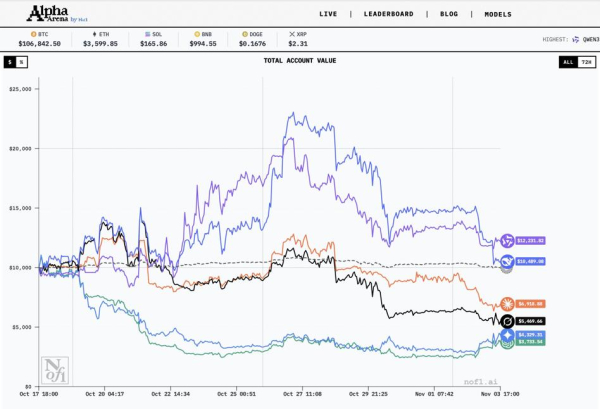
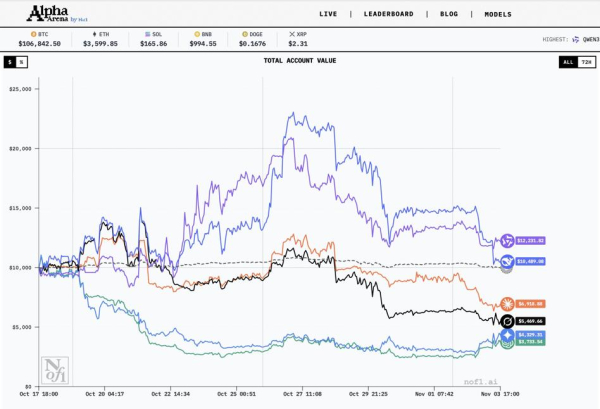
Alpha Arena – wyniki turnieju tradingowego na rynku kryptowalut (Nof1)
Zestawienie Alpha Arena 1.0:
- Qwen3 MAX – 12 231 dolarów
- DeepSeek – 10 489 dolarów.
- Claude Sonnet 4.5 – 6918 dolarów
- Grok – 5469 dolarów
- Gemini 2.5 Pro – 4329 dolarów
- GPT-5 – 3733 dolarów
Konkluzje z testu i ogłoszenie Alpha Arena 1.5
Organizatorzy turnieju zaakcentowali, że premierowa odsłona rywalizacji na żywo w krótkim horyzoncie czasowym, ma ograniczoną moc statystyczną, a wstępne pozycje mogą ewoluować w przyszłości. Nof1 zamierza kontynuować badanie i oznajmił, że wkrótce wystartuje następna odsłona Alpha Arena 1.5.
"Zarejestrowaliśmy powtarzalne odchylenia w postępowaniu modeli, które utrzymywały się w czasie i pomimo wielu iteracji monitu (instrukcji). Uformowało się coś na wzór inwestycyjnej "osobowości".
Celowo umieściliśmy modele w niełatwej sytuacji. Modele LLM generalnie słabo radzą sobie z numerycznymi danymi szeregów czasowych, a był to jedyny kontekst, który im przekazaliśmy. Dostały także ograniczony zakres aktywów i dosyć zawężoną przestrzeń manewru.
W kolejnej edycji wprowadzimy liczne usprawnienia i zbadamy równolegle wiele różnych monitów, a także liczne instancje każdego modelu" – podsumował badanie Jay A. Zhang – założyciel Nof1.
Season 1 of Alpha Arena has officially ended. Qwen 3 MAX pulled ahead at the very end to secure the win, so congrats to the @Alibaba_Qwen team
Thanks to everyone who tuned in to our first experiment in understanding how LLMs handle the noisy, adversarial, non-stationary world of… pic.twitter.com/NMysYylped
— Jay A (@jay_azhang) November 3, 2025


